
Achieving Enterprise Scale with Azure Functions
azure azure-functions 
A few months ago, I posted about creating a decoupled, scalable web store order fulfillment app using an Azure Web App (as a webhook), WebJobs and storage queues. This is great for ensuring that orders don’t overwhelm your infrastructure, but it makes an assumption that queue consumers will handle the peak traffic over time and a single instance of these WebJobs is enough to handle all of your orders.
But what about when that’s not enough? In enterprise solutions with enough throughput, we need a way to keep up with demand. In this post, I will talk about the basics of Azure Functions and will follow up with a subsequent post that talks more about development, source control and deployment options.
Microservices at enterprise scale with Azure Functions
Azure Functions are the next iteration of the WebJobs SDK – in fact, both of them run on top of that SDK. They are represented in the Azure portal as a Functions App, which is a component that comes with its own UX, built to allow creating, developing, integrating and monitoring functions directly through the portal. The UX is a quick way to get started as it requires very little effort to bind to components within your existing resource group(s).
Calling Functions “microservices” is probably overstating reality (I’ve more commonly heard them referred to as “nanoservices”), but it’s a quick way to conceptualize how they work and the purpose of using them in a solution. Multiple logical steps of your services can be represented by independently scalable Functions, which is powerful because now we can depend on Azure’s autoscaling capability handle our long-running, memory-intensive processes differently than the lightweight ones – ultimately keeping costs down.
On the topic of cost, Microsoft has two deployment options that use different pricing models and tend to support different use cases:
- Deploy your Function App to an App Service plan: this option is best when you have underutilized App Service plans (analogous to VMs as a service) you’re already paying for, since then there are no additional costs on top of the plan itself. You can deploy as many Functions and Function Apps as you like, but keep in mind that you’re limited to only the resources within your App Service instances (which can be scaled horizontally and/or vertically as usual). The best use case for deploying this way are for Functions that don’t need to scale, or for those that run often and are highly memory-intensive (I’ll get to that in a moment).
- Deploy your Function App to a Dynamic App Service plan: this option is where we achieve real scale – effectively, you are giving Azure a managed application package where an algorithm decides, within your region of choice, where to deploy your code and how many instances to deploy based on usage rules. Since you’re not using an existing App Service, new pricing rules apply which are determined by number of executions and memory usage. The use case here is Functions that have a relatively low runtime and are less memory intensive, and/or need to operate at significant scale. The Dynamic App Service deployment is what is currently being called a “serverless” application, since you don’t have to do any infrastructure provisioning to make it work
How do Functions work?
Functions are defined by directories hosted under the Function App’s application root, where the directory name represents the function name, and the function’s internals are defined by the following file structure:
- FunctionName - the directory name will also be the Function’s name in the Azure portal
function.json- this file defines the Function trigger and binding(s) (more details to follow)run.csx- since I’m using C# in my implementation, this is the C# Script definition of my function’s code - your Function could alternatively use Ruby, Node, PowerShell, F#, depending on your preference and skill set. A C# Script requires that I include a public static Run method that takes the trigger and binding(s) as parameters. At the moment, C# Scripts don’t support Intellisense - this is something on their roadmap
A Function’s definition, managed by a function.json file in its directory, has three primary concepts:
- Trigger - triggers are what cause Functions to execute. These are most commonly HTTP (requests and webhooks), Timers (chron jobs) and queues (Storage and Service Bus), but include several other options
- Input Binding (optional) - triggers can pass in identifiers that can be used to query data from storage components. For example, the route
/functionName/{id}paired with a Table Storage input binding will pass the matching strongly-typed table record into the function - Output Binding - these are references to storage components as output of your Function. An example would be Table Storage, where the Function would store the trigger’s data to a database. You can pass in multiple output bindings, and since they are being passed in by reference, any items added to these outputs are automatically sent to the corresponding bound resource without including them in the return statement of the function
For more details on triggers and bindings, check out the developer reference: https://azure.microsoft.com/en-us/documentation/articles/functions-triggers-bindings/
A real life implementation example
My journey into Azure Functions has been mostly comprised of refactoring my existing webstore fulfillment app away from WebJobs and into Functions. It is admittedly overengineered based on current sales traffic, but Functions at low scale are so inexpensive that it ended up being a good opportunity to implement some new features. Here is my updated conceptual solution architecture using Functions instead of WebJobs:
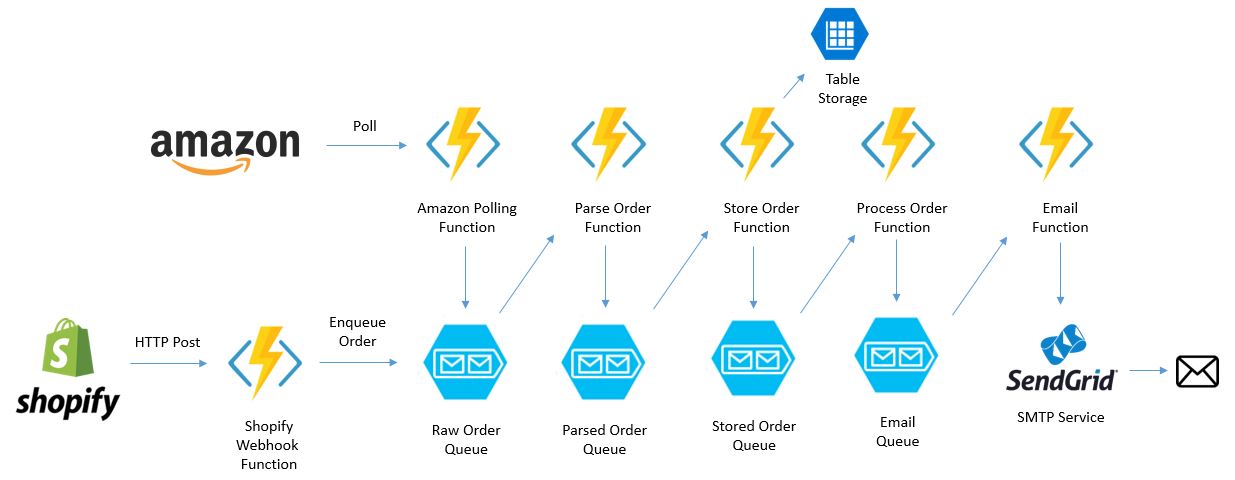
Apart from being massively scalable, this architecture allows each Function to do one simple thing that it’s very good at and nothing more – helping manage cognitive load by ensuring that the developer is working only on one thing at a time.
For error handling, I pass three queues into most of my Functions as outputs, [queue-name], [queue-name]-error and my email queue. If something goes wrong, store the message in a separate error queue so that I don’t lose access to the raw message - also, there’s no reason later on that I couldn’t create resiliency Functions to drive reprocessing of failed messages in certain cases. On top of that, I send myself an email using my email queue and Function to alert myself to go take a look to investigate. The monitoring functionality in the Functions UX is solid and captures plenty of information useful in debugging.
Based on my use cases, I split out the Functions into two applications. The PollAmazon Function runs every 10 minutes and has no reason to scale, so I decided to host that on my existing App Service where I’m already hosting their public website as a Web App. Alternatively, the order handling Functions should be autoscaling, so they are hosted in a Dynamic App Service plan.
This covers the basics for now. I’m planning on following up with a post that gets a little more technical in how to set up and deploy Functions.
Share this post!